
The Great Splunkbundling
Logging infrastructure & the SIEM stack weren't built for 2020. Splunk dominates this category, but will get disrupted by best-of-breed tooling.

Thanks for being here! Every month-ish, I’ll publish a new thesis, interview with an enterprise operator, or commentary on happenings in b2b land.
Right now, I'm thinking about investment opportunities within the SIEM & logging infrastructure stack, and ways to disrupt Splunk from a technical perspective. Thinking about similar stuff? Shoot me a note at rak@ov.vc or on Twitter!

When I shipped audit & activity trails at Atlassian, I met dozens of senior leaders in IT and security across six continents who all relayed some version of the following story:
I'm the global security lead at BigCo, and I need to make sure no one's leaking our product roadmap out of Confluence and Jira. How do I make sure this hasn't already happened? And if it does happen, how do I make sure I'll find out as soon as it does?
The answer is to use an SIEM (security information and event management) tool like Splunk. As the dominant platform, Splunk ingests data from disparate sources, indexes it to make it queryable, and lets you build dashboards and alerts so you'll know when things go wrong. Common use cases include:
Satisfying data retention requirements (up to 7 years in regulated industries).
Monitoring internal and external threats (i.e. upset employees downloading your Salesforce prospects before heading to a competitor)
Alerting response teams in the event of breaches
Monitoring service uptime and performance
But Splunk is an expensive, manual, and complicated product. Best-of-breed tooling will disrupt various parts of the SIEM stack thanks to downward pricing pressure, robust workflow automation, and simplicity.
The Splunk Story
When Rob Das and Erik Swan decided to start a new company in 2002, the pair asked engineers at 60+ companies in verticals ranging from healthcare to manufacturing to technology how they deal with infrastructure problems at work. One of their friends likened the process to spelunking; discovering and remediating infrastructure problems was like crawling through mud, in the dark, with a dim headlamp and sharp things jabbing you in every direction.

The analogy resonated with all of the people they surveyed, and the company they would eventually start became known as Splunk. But spelunking was only an apt analogy when there was data to crawl through. Most of the time, data existed in unstructured & unreadable formats, and was fragmented across silos in the organization, causing companies to hire:
Infrastructure engineers to produce robust logging systems that would generate data.
Database admins to store, structure, and query the data.
Security engineers to write Perl scripts to automate discovery and throw alerts.
Data analysts to visualize and correlate events and alerts, capturing business value.
As infrastructure complexity grew, log volume grew exponentially, and companies were forced to hire more people to deal with the workload. Greater organizational complexity made it easier for teams to point fingers, corroding the manual workflows that were in place and making it impossible to uncover, let alone maintain, a source of truth. Splunk saw some version of this blame game playing out in a bunch of orgs, signaling that companies a) needed a way to distill truth from logs and b) would pay lots of money to not have to hire massive teams to deal with a).
Around the same time in 2004, a little company called Google was just gaining popularity, and that's when Erik and Rob formed their thesis: Splunk would be Google for log files. They raised venture capital in 2004, and got to work building a log management system for engineers, by engineers, birthing the SIEM category in the process.
Splunk's Advantage
Splunk's core product, core GTM, and core pricing model remain relatively unchanged in the 18 year history of the company. In 2011, Splunk had ~300 employees. Today, it's pushing 7,000. Their 2020 Q3 earnings showed a ~40% increase in ARR on a YoY basis. Splunk has two main advantages that make its core business so enduring: flexibility and vendor lock-in.
Flexibility
The core advantage of the Splunk platform is its flexibility in ingestion breadth and deployment options. Tight integrations with peer platforms deepen Splunk's moat.
Ingestion: Splunk is like a kitchen sink cookie; it’ll take anything you throw at it, and most of the time, it’ll get the job done. Splunk can ingest data from IoT sensors, network devices, mobile devices, and more, in unstructured machine data formats, all in real time. This effectively replaces the need for specialized BI engineers and DBAs to construct ingestion pipelines and polling systems.
Deployment: Splunk offers on-prem and cloud deployment options, allowing companies that have already made large capital investments in physical infrastructure to use Splunk more affordably (on an annual, not TCO, basis). Splunk introduced a cloud offering in 2013, expanding access to companies that were either making shifts to cloud-only environments or were cloud-native.
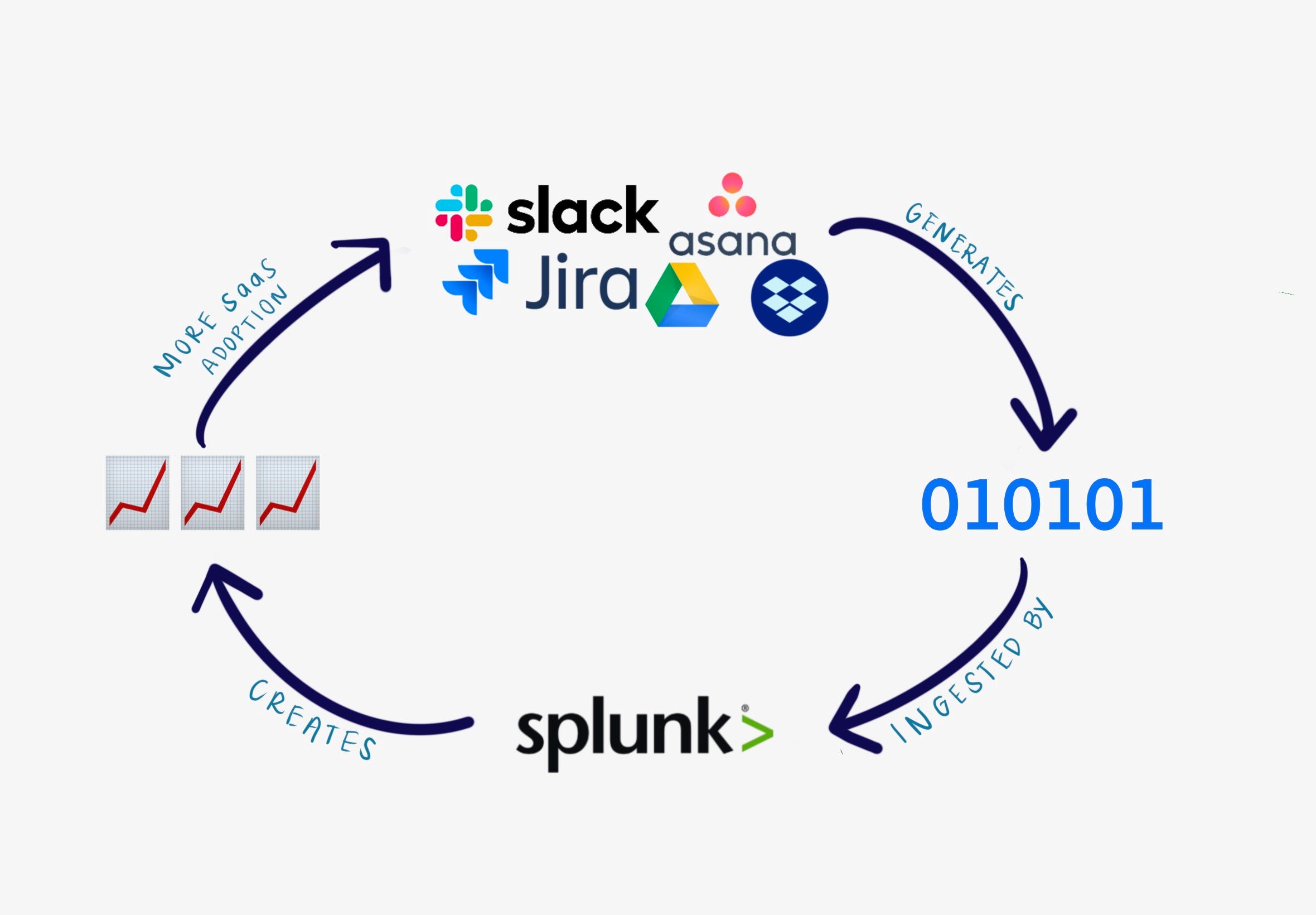
Platform: Strategic partnerships with cloud platforms like GCP accelerate Splunk's adoption and deepen its moat in organizations that are attempting digital transformations, either via virtual private cloud deployments or public cloud implementations. Tight integrations with leading SaaS providers make the risk & compliance case for companies transitioning to the cloud easier, creating a flywheel of SaaS adoption and increased need for Splunk.
Vendor Lock-in
Splunk's flexibility derives from its sheer power and agnosticism towards data formatting, but harnessing that power often requires customers to hire trained experts well versed in Splunk Query Language.
Certifications: Splunk and its channel partners offer a swath of courses and certifications that people build careers on the back of. This solidifies lock-in at companies where Splunk is already deployed, but also introduces barriers to entry for startups that haven't yet built security operations teams.
Custom query language: querying indexed data in Splunk in a custom language indirectly increases the cost and delays payback for any alternative vendor a customer might churn to. Would you use an alternative, if all of your queries and dashboards have to be redesigned from scratch? This is both offensive and defensive; a custom language can harness the full power of Splunk on complex datasets, while preventing customers from churning.
Opportunities for best-of-breed solutions
Splunk works, especially for F100 enterprises that are bought in. However, from my conversations with several CISOs, I believe Splunk's advantages are eroding for the following reasons:
Complexity. For less complicated use cases like log retention, compliance, and daily monitoring, using Splunk is a bit like driving a Boeing 787 to go 5 miles in traffic. It'll work, but you'll wish you had a scooter instead.
Security orchestration, automation, and response (SOAR) workflows must be defined in Splunk manually. Next-gen tools that auto-generate probabilistic SOAR workflows and reduce the need for hiring a specialized SecOps team have a good chance of ingraining themselves within a typical security organization.
Pricing. Splunk is expensive, at $1800/GB/year. To put things into perspective, one gigabyte of indexed logs would maybe serve a small 5 person startup's operations for maybe a few weeks. Companies that compete on absolute price or help customers reduce the amount of log info they send to Splunk have a massive opportunity to capture Splunk spend.
Splunk's architecture contains three systems: the forwarder, indexer, and search head. There are direct competitive opportunities in each layer in the architecture, as well as adjacencies between layers for spend optimization.

Forwarder
The Splunk forwarder collects data from a bunch of places (think sensors, APIs, firewall appliances, etc), and sends it to the indexer in real time. The indexer stores and indexes the data on disk, and is agnostic to the data that it receives from the forwarder, so anything that hits the indexer counts against your data allowance from Splunk.
There are two clear opportunities here:
Pre-processing data and dropping unnecessary fields before it gets to the indexer.
Re-routing data from hot to cold storage, exploiting cloud cost structures.
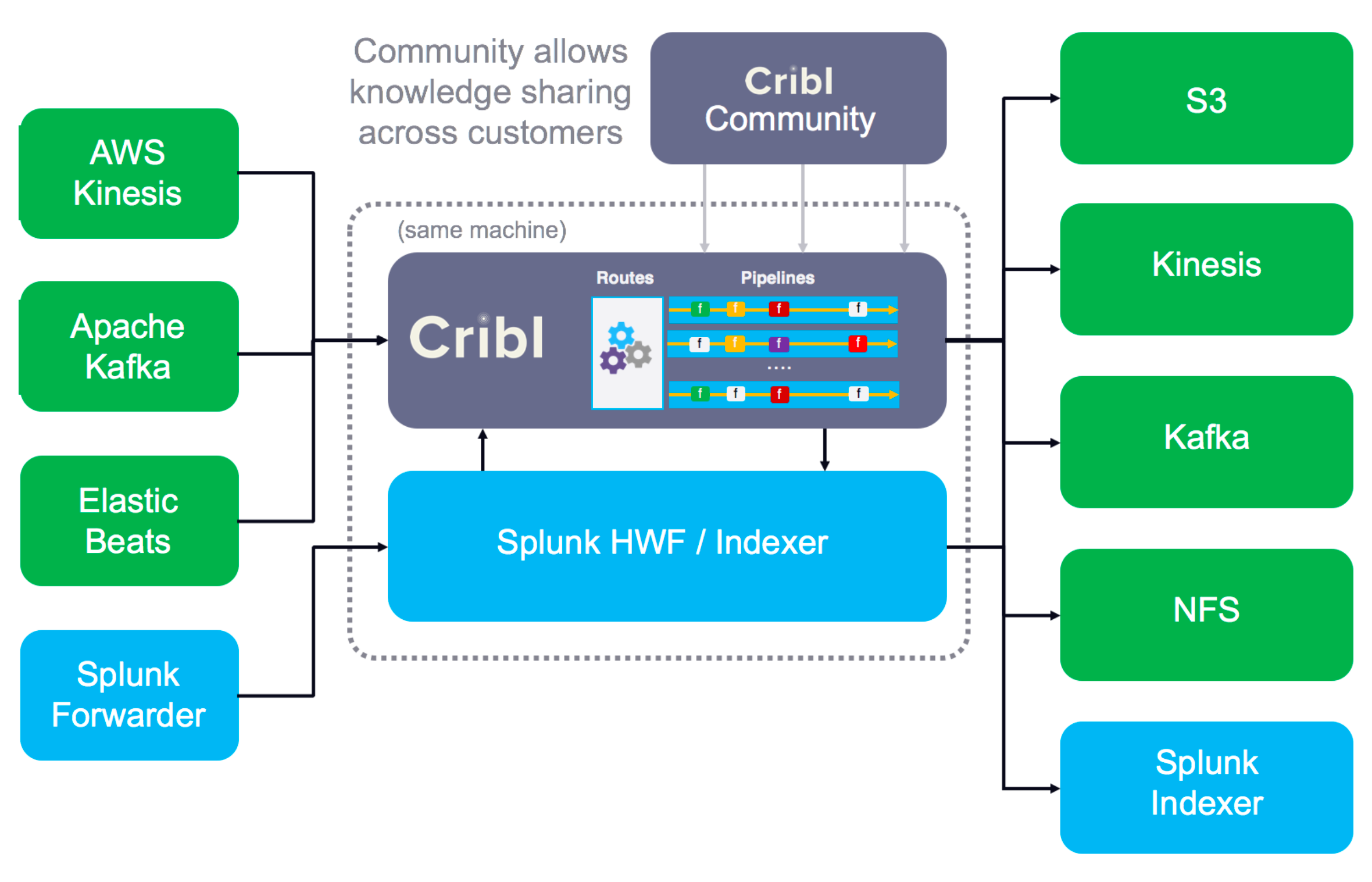
Cribl is one my favorite companies tackling both. A typical logfile contains metadata like browser agent, IP address, MAC address, network headers, latency information, location, temperature, etc for events generated every nanosecond. Not all metadata is helpful in running security analyses, so Cribl removes useless information, reducing volume & cost, and accelerating indexing.
Storing logs in hot vs. cold storage also heavily influences costs. According to Cribl docs, sending event data to cold storage via Cribl can save companies 97% of their storage costs!
If 1.8PB [is] the total storage, at a monthly cost of about $180K (based on list AWS EBS pricing), or about $2.2M per year. That’s a pretty large chunk out of even the best-funded security team’s budget. However, move that all to low-cost archive storage, like AWS Glacier Deep Archive, and that monthly cost goes down to about $5400 per month or $65K per year.
Log pre-processing tools are not just value capturers, they are also value creators in that companies that leverage them can run faster security analyses, reducing time to breach detection and risk.
Indexer
The Splunk indexer ingests data from the forwarder and builds an index so that the data can be queried. There are multiple issues, though:
Splunk isn't a cloud-native platform, so scaling up processing cores with data volume is still a manual process with pricing implications.
Splunk's custom query language, while great because it can handle unstructured data, can still take hours or days to run on large datasets.
If you're using a preprocessor to save on costs, Splunk will only ever have one part of the whole picture, because giving it access to all data would be prohibitively expensive.
That's where tools like Snowflake and Panther can have a big impact.
Snowflake for more affordable storage
Snowflake's cloud-native data lake scales automatically, with unlimited querying that can be 200x faster than traditional SIEM querying. Whether logfiles are structured or not, Snowflake can be used to store everything in one place, so all data is centralized and shareable beyond just the security team's purposes.
Given that the average time to detection of a breach is >9 months, a unified data lake with faster querying can make the difference in helping teams make faster, more informed decisions. Snowflake can be used in conjunction with, or in place of, traditional Splunk indexing. BCV's team has done an excellent job crystallizing next-generation analytics opportunities to be built on top of Snowflake.
Where Splunk costs might only let you store 7 days of logs, a Snowflake implementation could let you store logs for a year or even longer for the same price. Regardless of where Snowflake sits relative to the SIEM system in an organization, it offers greater flexibility, speed, and cost-savings over a tool like Splunk in both data storage and data analysis costs.
Panther for more flexible investigating
Panther is a full-stack SIEM solution, differentiated by its use of Python, allowing for more expressive and transparent analyses while lowering the need for a company to find an expensive Splunk expert to set up a SIEM tool for them.
Panther democratizes access to sophisticated security analysis and orchestration, through a) query language and b) startup friendly pricing. Panther can also run pre-processing on logs before sending to a data lake like Snowflake, reducing costs even further.
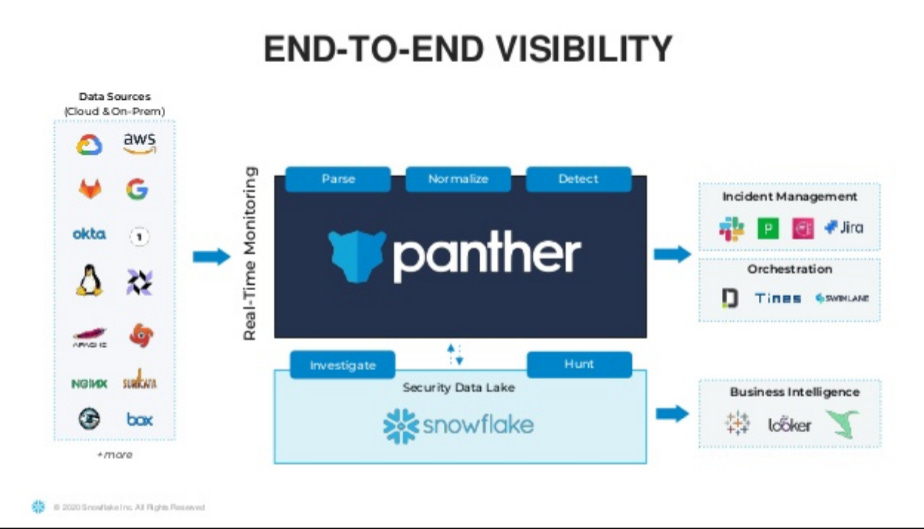
Pre-built rules and a far more user-friendly remediation platform make Panther the tool of choice for companies that either don't have or don't want to make the investment in a costly legacy SIEM solution.
Search head
The Splunk search head is the interface between users and log data. Once you’ve setup data ingestion (whether it lives in AWS cold storage via Cribl, in a unified Snowflake instance, or in Splunk), automated alerting to help you catch fishy behavior is a must.
In any mature organization, you’ll deal with thousands of alerts a week. How do you know which ones need special attention? SOAR (security orchestration, automation, and response) tooling helps security engineers deal with volume. Splunk acquired Phantom in 2018 to connect, coordinate, and automate security actions with custom playbooks.
Companies like Tines offer unlimited-step automation workflows that can be used to build chat bots, automatically respond to phishing emails, page on-call, and handle employee off boarding to limit data exfiltration. Where Phantom works with pre-defined apps, Tines works with any tool that has an API, letting security engineers use any app that’s already in their workflow, including custom internal apps.
It’s tough to see Splunk making Phantom as platform-agnostic as Tines is, and Phantom's lack of flexibility, pre-built rule definition, and step-limited automation engine makes Tines a superior SOAR tool, whether you use Splunk or a combination of best-of-breed tools as your SIEM stack.

Opportunities for event producers
SIEM is an event aggregator. Log files generated by event producers are ingested by Splunk and then acted upon via orchestration and automation workflows. The problem with this model is that even if you had the perfect SIEM solution for your company, conclusion quality will always be closely correlated with event quality.
Two clear opportunities here are to:
Reduce the amount of false positives generated by Splunk
Replace noisy network appliances with tools that are more thoughtful about event generation and flagging.
False positives
One of the core issues with any SIEM is that even with pre-built alerting and event triggers, the sheer volume of information that enters the pipeline leads to false positives distracting security teams from actual problems. Pre-processing helps in reducing false positives, but it isn't a complete solution because you still need a critical mass of event information in the SIEM system to draw accurate conclusions from it.
A complementary solution is to combine real-time data stream processing with ML models to proactively reduce false positives. Wallaroo is one of my favorite companies accelerating production model scoring and testing, helping CISOs (and other data-intensive verticals) quickly leverage ML model-building and deployment while keeping the need for data scientists down. Using something like Wallaroo introduces the possibility of non-linear event correlation to build greater context around security events when they happen. Today, most event correlation handles linear streams of data, but sophisticated attackers leave behind seemingly disconnected trails of data that linear analysis can't uncover.
Noise reduction
As part of the shift to non-linear SIEM systems with low false positive rates, scrutiny will shift inward when companies realize they can't rely on VPN and traditional network logging to determine internal threats. We're already seeing strong tailwinds to accelerate that shift, since companies no longer find IP-based allowlisting or behind-the-firewall appliances as reliable ways to secure network traffic in a remote-first and distributed world.
Companies that address internal networking challenges in a security-first way will be loved by CISOs that are deploying SIEM systems over the next decade. One of my favorite companies in the space is Meter, which integrates SSO and threat monitoring into the ISP stack, so that companies that subscribe to Meter for internet are covered from day 1, without needing to buy, setup, and integrate costly network monitoring appliances themselves.
Because Meter integrates with SSO, it can more easily stratify network traffic along employees' identities, making it easier to pinpoint origination and get to the root cause of internal network-related events. This is a cleaner, less noisy approach to traditional methods of network monitoring, and results in faster time to resolution when ingested by an SIEM system.
Twingate is another company disrupting the traditional VPN model, which is costly to maintain, performs sub-optimally since all traffic has to go through the VPN even if it doesn't need to, and has a wider attack surface since VPN portals are on the public internet. Twingate leverages split tunneling, so that only the network traffic that accesses critical information will enter the company's secure network, drastically reducing log volume. An SIEM implementation would then see far fewer network events, reducing costs in volume and noise.
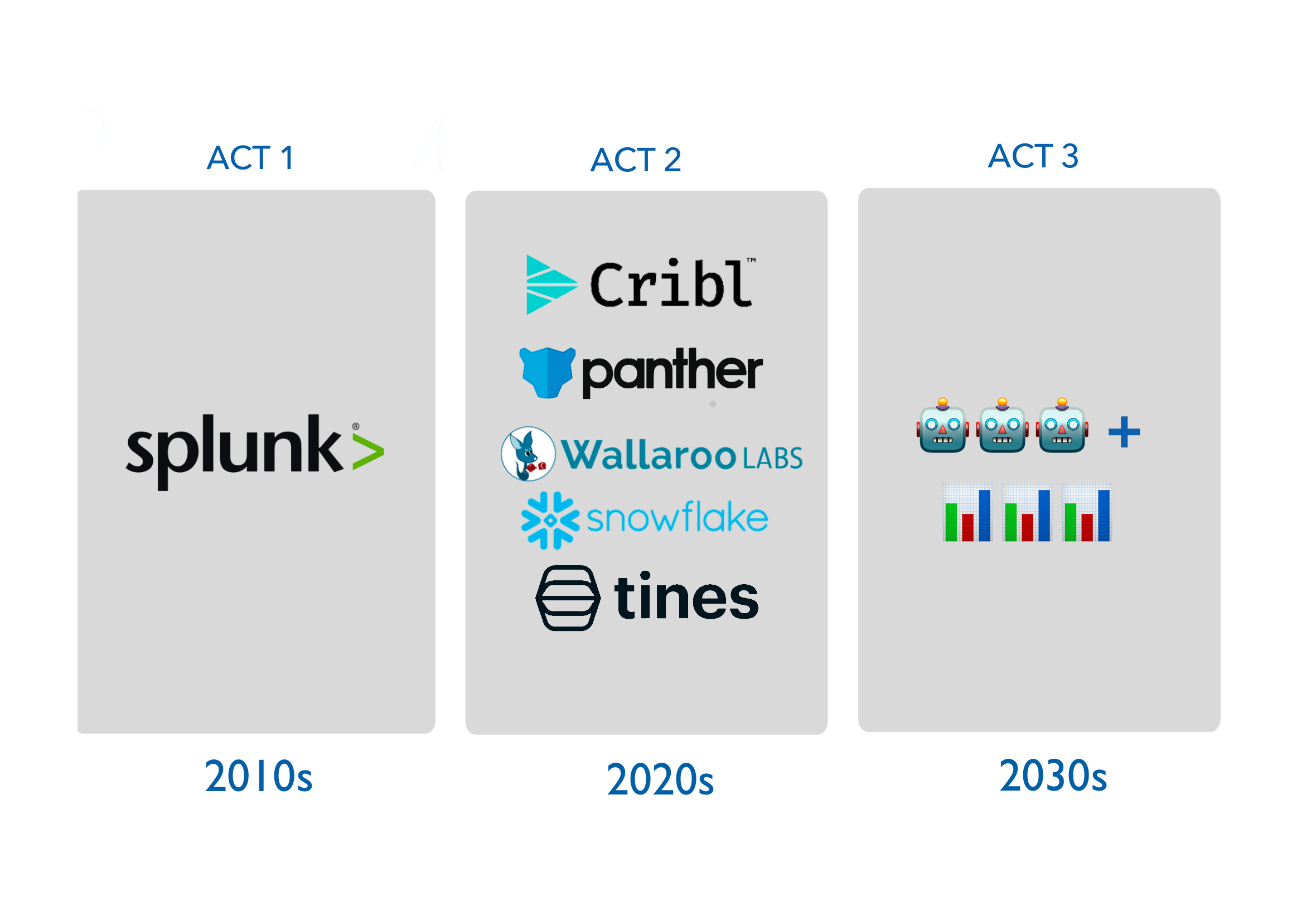
Three acts of SIEM
Crystallizing this piece into three acts, I believe we are at the close of Act 1 and at the cusp of Act 2.
Act 1 was Splunk - a kitchen sink platform that unifies all data for maximum visibility and discoverability. This was a generational shift that characterized SecOps for the past 2 decades, but exploding data volume and drastic reduction in cold storage costs necessitates a transition to Act 2.
Act 2 is an SIEM stack composed of best of breed tooling like Cribl (log pre-processing) → Snowflake (data lake) → Panther (parsing) → Tines (orchestration). These tools solve the cost and analysis at scale problems that plague Splunk and will define security operations for the next decade, but don't address the core issue of event fatigue and high false positive rates.
Act 3 will augment the SIEM stack by opening adjacencies to MLOps tooling and less noisy internal network security monitoring. Where Act 2 focused on improving the way we deal with linear streams of data, in Act 3, security teams will have fewer, and higher quality, network activity logs and can link seemingly disconnected events together, speeding up analyses and enabling greater automation.
The legacy SIEM stack will be disrupted by best of breed tools that both increase security teams' productivity and their ability to discover issues. Logs are still the de-facto source of information in root cause analyses, and tooling to make log processing easier presents an immense amount of leverage for both CIO/CISOs and individual security engineers.
I saw both the value and demand for more effective logging and security orchestration when I was a product manager at Atlassian, from companies ranging from 6 person startups to large F100 enterprises.
If you're building in the space or have thoughts/feedback, find me on Twitter or drop me a note at rak@ov.vc!
Thank you to my incredible friends Nandu, Graham, Shomik, Corinne, Lindsey, and Yash for the edits, feedback, and support!
Loads of good and deep information, thank you for the research.
The premise of your article, if I understand it correctly, the idea that one needs a SIEM to help not leak IP out of an organisation is not complete. I would like you to elaborate why you think there is a link between the two. Sure, SIEM's can help, but that is not the complete story.
Regarding the timeline and tools you are proposing to replace Splunk: if I understand correctly, you want to propose to replace one single expensive tool with at least 3-4 components/vendors/tools to do the same thing. Do you think that scales? How many FTE's will you need to build the integrations, maintain the content and workflow? We are back to the build vs buy - of course, you can always build which has it's added benefits, but some businesses just want to focus on their business and not on reinventing the wheel.
My take on innovation in this space: the real disruptors that will actually help shape the change in existing solutions will be the Cloud stack providers: Azure, GCP, AWS. If you look closely at Azure for example and how it is coupling it's services and ultimately offering and end to end stack for developers with built-in "good enough" security, you will soon realise they are have been listening to the developers (finally, right? MS doing the right thing, I cannot believe myself of saying this :-) )
I've seen myself many F100 try the build vs buy over the years, moving from one to another and buy always wins because of risk mitigation, total cost of ownership, time to market (which is crucial nowadays). If you are small and nimble and can hire 2 FTE's to put together a good enough ELK stack and maintain it for you security and logging, why not. But pulling together several quite costly paid service to do it when I have opensource to do the same, I still asking myself after reading your blog - why would I?
Have you considered Grafana Loki? The hosted version is 0.5$ / GB and it’s natively built for Cloud and Logs