
Five Predictions for AI in 2023
Tl;dr: unstructured streaming ETL, new hardware architectures, middleware to power LLM-based app developers, workflow execution, and generative content

Special thanks to my colleagues Sam Crowder and Dawit Heck for their work on this post, which originally appeared on BCV’s website.
We’re living in a special time; we have the compute, funding, and expertise to augment wide swaths of knowledge work using foundation models (also referred to as large language models or LLMs in NLP use cases). But despite their near-magical characteristics, foundation models are held back from practical usage due to a variety of technical constraints.
State of the World Today
Before we get into the weeds, let’s cover what makes foundation models, well, foundational.
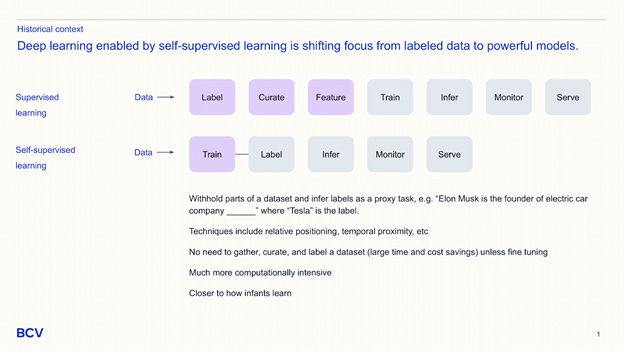
Emergent behavior. As parameter count and training data volume scale, LLMs exhibit new behaviors implicitly. In-context learning, which enables LLMs to perform lightly specialized tasks based on user input rather than a full fine-tuning process, is an example. Previous generations of NLP models were tightly coupled to tasks. LLMs have powerful generalized capabilities, including code completion, pattern recognition, dialogue, jokes, translation, search, and more. We expect to discover new behaviors as new models and training techniques are tested.
Ease of use. In a classic supervised learning process, data engineers and data scientists collaborate to ETL, label, curate, and featurize data before training and generating inferences. Companies like OpenAI and Stability.ai host pre-trained models, enabling users to generate inferences without data wrangling or training. Self-supervised learning makes this possible, where various words are withheld from a sentence and the model is expected to predict the missing word.
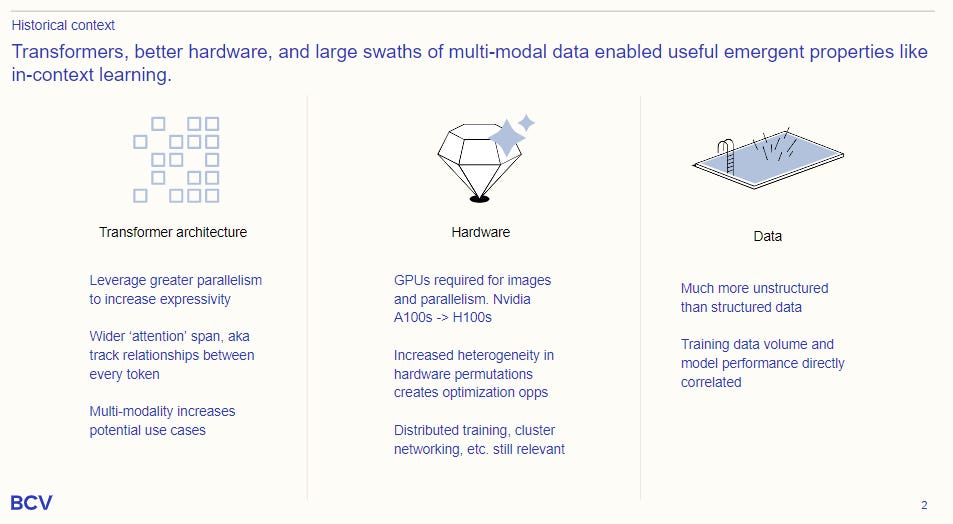
These are exciting developments, made possible by the transformer architecture, which couples a block of encoders and decoders through a self-attention mechanism. It has become the state-of-the-art approach for self-supervised pre-training in NLP and sequence learning. Put very simply, self-attention enables the model to maintain an understanding of the relationship between every position in the input and output sequences. The encoder converts the input sequence into a set of vector embeddings, which are long strings of numbers to represent natural text that the model can reason about. The decoder converts the embeddings into a different sequence of words, or an image, or some other modality.
A transformer model’s ability to process the entire input all at once has less complexity and compute cost relative to legacy neural networks (i.e. RNNs). Prior approaches had narrower attention mechanisms, harming model performance. The result has been the rapid development of a series of LLMs that can more accurately perform tasks across text generation, image generation, code generation, summarization, translation, and much more.
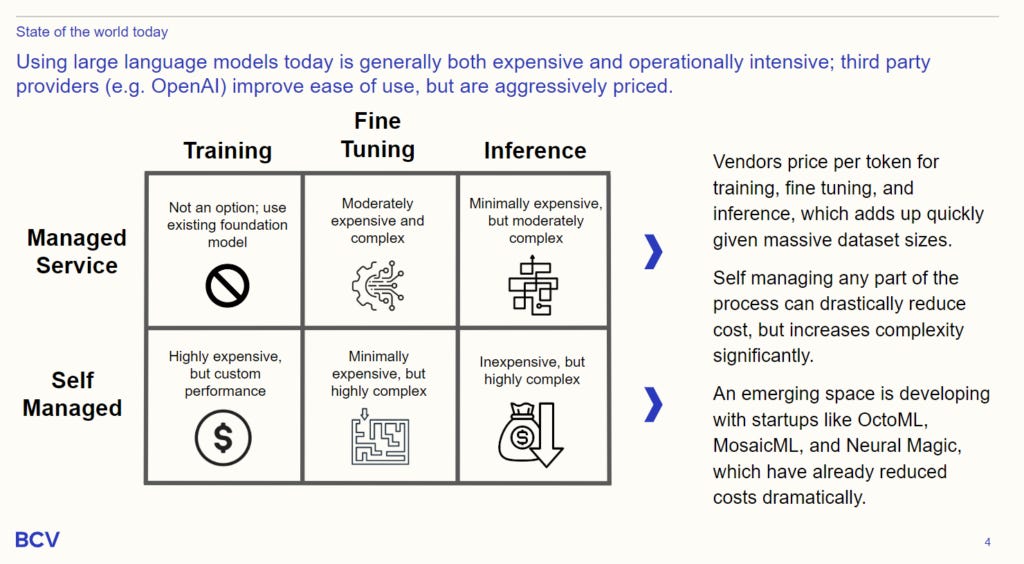
Smaller AI companies have a structural disadvantage competing against incumbents due to both computational intensity and the increased data volume advantage that scale brings. Almost without exception, initial foundation models came from the largest technology companies: Google, Facebook, OpenAI (funded by Microsoft), and NVIDIA. We expect the cost of training, configuring, and running foundation models to increase as models grow in parameter size, data advantages incentivize more creative data extraction techniques, and chip shortages continue to exacerbate compute innovation and capacity. Today, well-funded startups like OpenAI and Adept, large corporations like Microsoft and Google, and research groups at top universities lead model R&D and drive the pace of new breakthroughs.

Getting Into Production
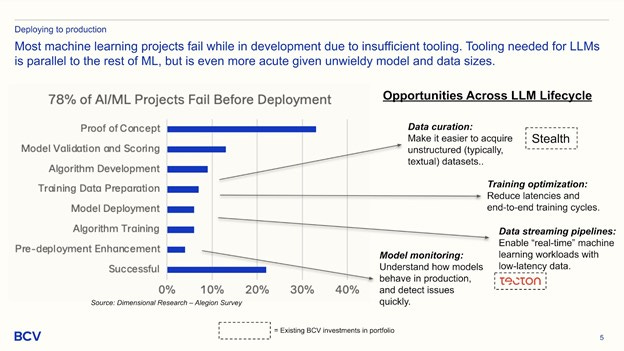
Productionization, as many ML engineers know, is a trade off between complexity and cost, but often an unavoidable amount of both. Most ML projects fail before they get to production. We are optimistic that proof of concept complexity will decrease in the coming years, as products like ChatGPT unlock the imagination of everyone from software engineers to people-ops leaders. Downstream, model fine-tuning is reliant on curating large swaths of unstructured enterprise data. Optimizing training latency and cycle time is an outsized opportunity, given model scale and complexity. Users demand that modern applications be highly interactive, and as “real-time” as possible, increasing emphasis on data streaming platforms.
Optimization Techniques
While the primary axis of competition so far has been parameter size, the research community is increasingly focusing on new optimization techniques to make models easier to train, use, and deploy with greater accuracy. One such example is DeepMind’s Chinchilla, which has ~4x fewer parameters, but was trained on ~4x more data than Gopher and could perform at parity. Consequently, we believe large models are severely undertrained, suggesting that we’re not compute constrained, but rather data constrained. (Andrew Ng continues to be correct about data-centric ML!)

One newer approach to model optimization is sparse activation (e.g. Google Pathways architecture), which avoids activation of the entire neural network and instead activates very specific pathways as needed, reducing compute waste.
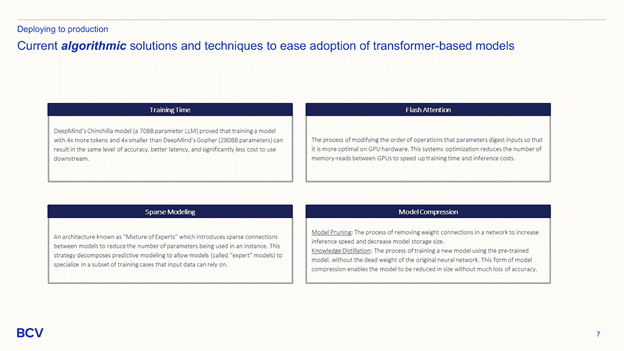
Earlier, we mentioned that transformers use self-attention to simultaneously track the relationship between each input position and output position. This scales quadratically with sequence length, contributing to much higher training costs with larger sequences. However, in many production use-cases, larger sequence lengths are needed to appropriately train and specialize models for specific contexts. Not to mention, larger sequence lengths create a new set of training opportunities for large models.
Tri Dao and Chris Re at Stanford have done a tremendous job with Flash Attention, which gives attention mechanisms IO-awareness, enabling them to account for the cost of reads and writes between various tiers of GPU memory and then using tiling (exploiting locality) and backward attention to be more efficient. The memory demand is nearly 5-20x lower, with 2-4x faster execution than those of exact attention mechanisms. Jason Brown and Yiren Zhao of Cambridge posit Wide Attention as another optimization over exact attention, where models are made shallower (fewer layers) with greater number of attention heads per layer, and found performance gains. Knowledge distillation, or using a pre-trained model to train a new model, is also seeing promising results, e.g EleutherAI’s Pile or DeepMind’s ZeRO. This technique avoids the dead weight of the original model, plus removes a key GPU memory barrier to building models with trillions of parameters.

At the hardware layer, we are seeing a transition from CPUs to GPUs to TPUs, which are more efficient for training massive (30B+ parameter) models. GPUs themselves are becoming multiples faster and cheaper, in part thanks to decreased demand from the crypto-mining sector, though some geopolitical and supply-chain constraints remain. Finally, higher bandwidth optical interconnects are emerging to power ML training clusters, addressing a network bottleneck.
Our Predictions for Foundation Models in 2023

We see great opportunity at every layer of the foundation model value chain, and are most bullish on the following five trends.
Unstructured streaming ETL goes mainstream. SaaS platforms at the application layer will continue to embed large language models into their core offerings, leveraging their data moats to fine-tune models and automate more of the user’s workflow. Streaming and the demand for real-time workloads will create new demands on unstructured data ETL and curation, because messy data will have to be extracted from new places to drive continuous improvement at the application layer. Companies handling streaming unstructured data workflows, curation, and ETL will become a core unblocker.
New hardware architectures emerge for foundation models. We will see new architectures emerge that are fundamentally better suited for large-scale machine learning. Model parallelism is one such architecture, allowing systems to map a model’s various network layers on a large on-chip SRAM array and avoid expensive memory transfers. Just as GPUs proved to be superior to CPUs due to their ability to leverage greater data parallelism, architectures that can make full use of model parallelism are well positioned to run the workloads of the future. Companies like Graphcore and Cerebras are innovating in this space.
The LLM economy comes online. While LLMs can be used for several use cases, not all of those use cases will become independent companies. Instead, many will be internal tools or smaller SaaS apps with limited audiences. We believe new tool-building products will emerge that power the LLM economy, enabling users to create AI apps at varying levels of abstraction, from serving APIs to drag-and-drop builders. Dust, Langchain, Spellbook, and BaseTen are good examples.
Models execute code, instead of just writing it. While text generation is quite helpful for writing code, it’s not as useful for driving downstream action. Large models will increasingly learn how to reason about and execute code, driving workflows end to end across disjointed sets of apps and functions. We anticipate this intelligence to permeate all aspects of computing, from routing data and traffic to eBPF-based kernel and application optimizations on the fly to executing workflows as needed.
Early versions of multi-modal models will inspire us. Multi-modality will enable models to create, reason about, and optimize content in new ways. Imagine shooting an iPhone video and having a model auto-correct it for image stabilization and audio quality on the device itself, or a future Netflix that generates movies tailor-made to your preferences. Imagination will be the blocker once large multi-modal models come online, and our world will look fundamentally different when they do.
> At the hardware layer, we are seeing a transition from CPUs to GPUs to TPUs, which are more efficient for training massive (30B+ parameter) models.
Why isn’t this a main investment opportunity? ie Google, Amazon who are leading the pack with TPUs